
Darren Montgomery, Filip Larsen, Daryl Waggott & Euan Ashley – Karolinska Institutet, Stockholm, Sweden / Stanford University, USA
“Olympic medal or not, Harald’s training regime would never be recommended in today’s era of high-intensity focus.” A classic example of different training protocols leading to the same outcome is the men’s 5000 m race at the last Tokyo Olympics in 1964. The three men at the podum finished within one second (13:48,8), where the winner Bob Shul (USA) focused on shorter harder interval sessions, the silver medalist, Harald Norpoht from West Germany, practised high volume training with mainly long slow runs, and the bronze went to Bill Dellinger who was a proponent of a polarized training regime.
It is blatantly obvious to everyone who has ever trained a group of people that everyone doesn’t respond in exactly the same way to the same type of training. Luckily, we are now entering an era where true individualized training optimization is becoming possible. This fact of individual differences has been known for centuries, but still the everyday practise in most sports and most clubs is to treat all athletes in the group the same. In a scarily high number of cases every player in, for example, a soccer team is exposed to the same training session. This happens even though some of them might have to run twice as far in matches compared to others, some experience much higher physiological loads in terms of high intensity running distance or number of accelerations and decelerations, a third group didn’t play the game at all, and a fourth group had a cold the previous week. The reasons given are usually lack of time and resources, and sometimes lack of knowledge. A great and experienced coach for a small group of elite athletes performs analysis and individualization every single day in the close work and conversation with the athletes. However, that is not scalable, so the underlying goal is to be able to individualize automatically. Such a system would help both the elite athletes pushing themselves to peak performance, but also the recreational athlete training a couple of hours per week. In the ideal world those few hours would be spent on the things that give the best improvements.
The first level of individualization is taking the specific demands of the game and exposure to training and games into account. The next level is to also consider the athlete’s individual profile. The demands might be exactly the same but there are personal differences in athlete response. An athlete that shows a rapid and large improvement following a training program is traditionally interpreted by the coach as gifted, whereas another athlete showing smaller improvements might be considered untalented. However the training response should more accurately be viewed as a highly individual sensitivity to the given stimuli. If the athlete does not respond to the training, there might be something wrong with the stimuli, not the athlete. We are using the term “exercise analytics” rather than “sports analytics” since the latter is commonly used for game performance statistics. Sports analytics was famously pioneered in the practical setting by the 2002 Oakland Athletics MLB team, as pictured in both the book and movie “Moneyball”. Since then, close to every single professional team added statisticians on staff that can readily assist with knowledge like “who should take the last shot from what position against what defender for the best chance of a successful outcome?”. This article is instead targeting the back end analytics asking questions concerning what type of training and recovery would be the right training for the right individual at the right time. One major difference is that sports analytics rely on game performance statistics which is accessible and available to everyone, but exercise analytics require access to all available information about the athlete, including retraining, test results, matches, subjective ratings, response patterns, etc. Sports analytics can therefore be done by anyone (with the right knowledge) and it’s possible to analyze all teams, whereas exercise analytics require access to training and test data and closer collaboration with the athlete(s) in questions in pursuit of understanding and optimizing their training and recovery. Genetics has a clear role in this aspect and is usually considered to account for ~25 – 50 % of physiological traits. Having said that, don’t waste any money buying any of the genetic tests available directly to consumers – these tests usually give you information about ~10 (up to ~50) genetic variants, a meaninglessly small portion of the >21,000 genes and 6 billion bases (positions that can be changed) that each of us possess. For coaches and athletes trying to achieve real results it is much more valuable to measure the outcome (physiology and performance) rather than the blueprint (genes).
“Everyone has data – No one has insight”
Technological advancements over the last decade or two have allowed for an explosion in data collection. Many sports have for several years used GPS- or video tracking for motion analysis, in conjunction with heart rate monitoring. This will add up to millions of data points from every single training session. On top of that, it’s common to collect subjective ratings, strength and conditioning testing, notes from the medical staff, markers in blood, urine and/or saliva. One soccer club that we collaborated with had almost 150 variables for each player! Unfortunately most device manufacturers just measure one thing, taking no notice of all the other aspects affecting the athlete, but still claim to offer a complete evaluation of the current status of the athlete. This leads to a situation where the coach and sports scientists are overwhelmed with data and analyses from lots of individual devices, sometimes opposing, and still have to do any truly comprehensive analysis manually. Because of the amount of data this is an impossible task, and the typical result is that the coach will either stop measuring or select a few metrics based on subjective and empirical knowledge of what matters for that specific sport or situation. That is an absolutely reasonable response to the “data tsunami”, but it doesn’t have to be that way. If you combine knowledge from data sciences including deep learning with human biology, exercise physiology, and sports performance you can build a system that creates a comprehensive and integrated view and give you (the coach or team sport scientist) insights and a decision aid for how to best handle each individual, without it taking any extra time for you. Needless to say, one must also be very careful when deciding which parameters to measure. Does that new fancy hardware actually measure your electrolyte balance in an accurate way? Is the questionnaire for mental stress validated and tested in elite sports? Is the new impedance meter sensitive enough to pick up tiny changes in body composition?
Optimization of training
This type of data driven decision aid has surfaced over the last couple of years, primarily with focus on analytics for injury prevention. That is understandable since it is the easiest aspect to quantify, and also the easiest to translate into data language, i.e. either you are injured on a given day or you are not (0 or 1). However, it is not a good primary target since the most prominent way of reducing injury is to train less and/or play fewer games. Instead, the long term focus for data driven decision aids should be to optimize training for each individual. Every elite athlete will have to balance on the edge of too much training, while avoiding injuries and illnesses, which is both challenging and valuable. The quest is to be able to tell when to go even harder or when to focus on recovery, and even more importantly to be able to tease out how much of each type of training that each athlete can tolerate, what sessions that give him or her the biggest improvements, and what variables are the most informative for that athlete. This might come across as a bit complex, but it is actually becoming possible to calculate optimal load for any given athlete in any given situation. As long as you have the relevant information, and an integrated analysis (Figure 1).
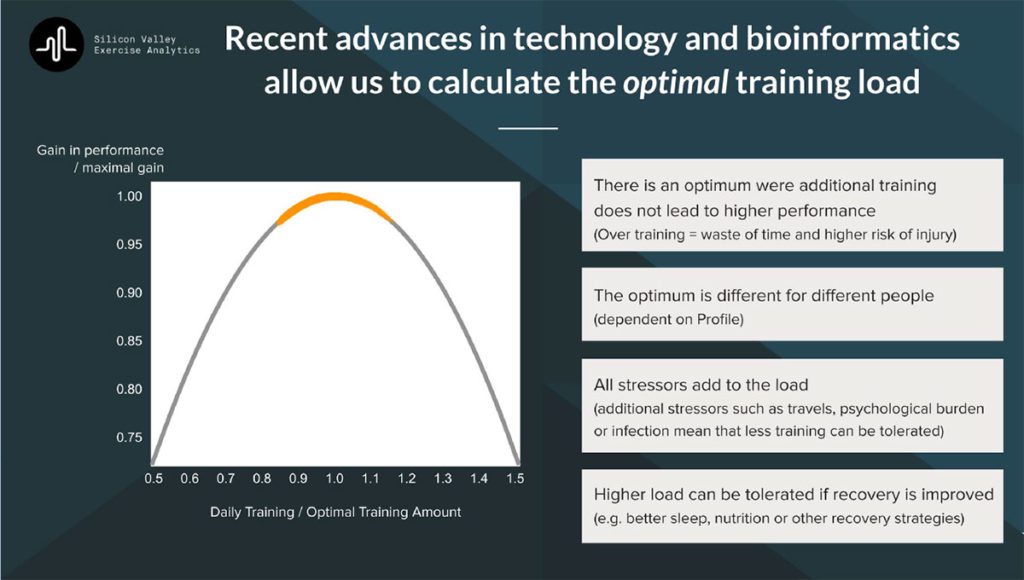
Everything must be included
A key phrase is “as long as you have all the information”. Another key aspect is domain knowledge. It is becoming increasingly popular to push products by saying something in the line of “Artificial Intelligence (AI) or machine learning (ML) driven/powered solution/platform”, however, without proper domain knowledge just “throwing AI at the problem” might improve your analysis, but will be far from optimizing the situation. There are a couple of problems that can be addressed pretty easily if you have a good understanding.
- AI can only take into account what you feed it. Are you measuring everything that matters? Do you have GPS-load and heart rate variability but not sleep, stress levels, or nutrition? For the AI to tell you what matters, you must gather everything possible.
- What are you training your AI against? What is the measured outcome? In some sports it is pretty easy, like swimming or running where the time is the final outcome, but how do you rate performance in team sports? Goals scored would be the easiest to quantify for the team, but clearly not sufficient for an individual player’s optimization analysis.
- Volume of data is not the major issue – Precision is! Contrary to many data and statistical situations, the total amount of data is not the biggest problem in exercise analytics, but instead the crucial factor is the amount and accuracy of the data you have about the specific individual. Current sport science models usually compare group averages, and state if one group/situation/intervention was different from another, but since the objective is to optimize each individual’s performance, it doesn’t help you to have millions of data points for other people in different situations. Instead you need a lot of data (years) about that person in order to build precision algorithms for an individual’s profile.
Figure 2 is a schematic view of the SVEXA approach. We gather “comprehensive” information about the athlete, run it through our clearly defined analytics process, and generate individualized advice with high precision. We recently performed the depicted analysis for swimmers going to the World Championships in Korea this August. In short, the coach has worked with these athletes for several years, and has empirical knowledge that within the group there is as high diversity of training profiles as at the podium of the 5000 m running at the 1964 Tokyo Olympics. We received access to training, test, and race data for the last two years, and set out to create algorithms for individual training optimization. Since this was the initial work with the swimmers, we didn’t adjust anything in their training. Instead, to test the accuracy of our algorithms we predicted the race times. To our great excitement the predictions missed the exact target by on average only 0.30 %, or 0.35 sec! With this level of accuracy you can actually simulate hundreds of different training programs for each athlete and pick the one that has the highest probability of success.
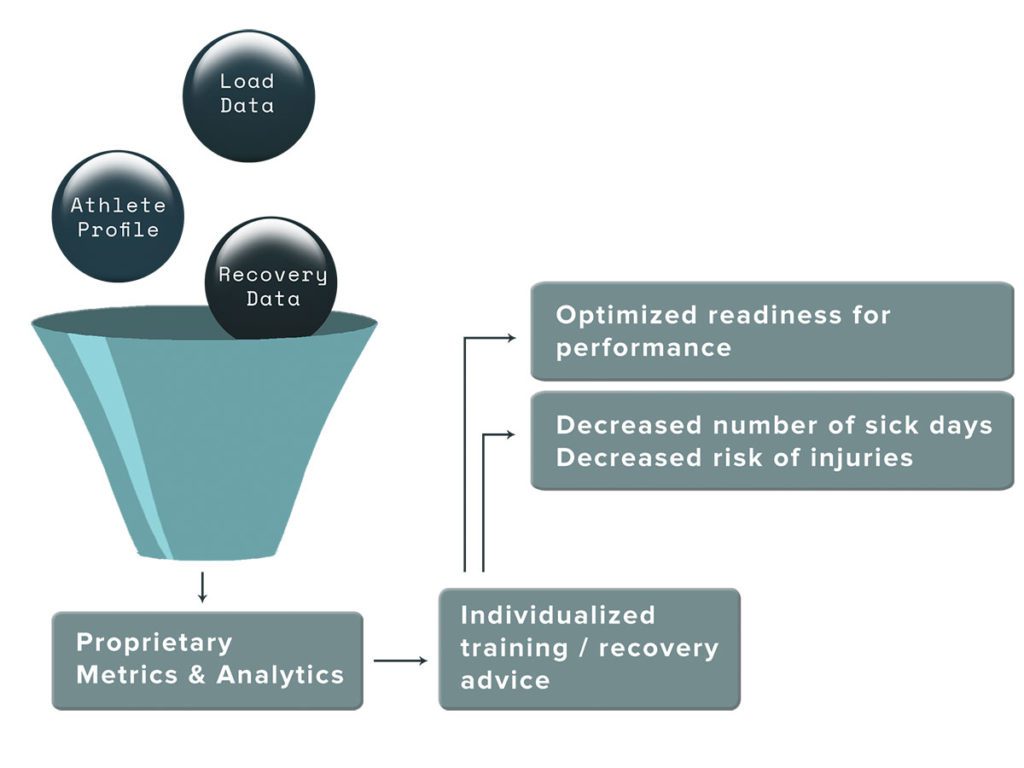
To conclude, in this new era, you should not settle for thoughts and guesses or inferior analytics, but instead know that it is becoming possible, with the right tools and knowledge, to use exercise analytics to truly individualize and optimize training programs.
For more information on how SVEXA could help your athletes optimize their performance, contact us on info@svexa.com
Autoren

is Expert Digital Health, with special knowledge in Precision Health, Exercise Physiology. Endurance Training, Exercise and the Heart, Sports Genetics, Mobile Health, and Exercise Analytics. He received his Ph.D. in Medical Sciences at the Department of Physiology and Pharmacology at Karolinska Institutet (Sweden) in 2011, where he is still affiliated and he has since 2012 held a research position at Stanford University, School of Medicine. Additionally affiliated to Silicon Valley Exercise Analytics (SVExA) (USA). Combined, his research at RISE, both universities, and SVExA is about optimization and individualization of exercise and physical training.


